2025年二季度,公募基金延续“赚钱季”势头!
根据天相投顾数据,2025年二季度,全行业产品盈利达3850.98亿元,环比增长1333.51亿元,增幅高达52.97%,连续第三个季度实现整体盈利。股票型基金以1204.79亿元利润成为主力,占全行业利润31.29%
基金管理人盈利榜单竞争激烈,11家公司利润突破百亿。
华夏基金以300.92亿元登顶,易方达基金(276.13亿元)、广发基金(249.77亿元)分列第二、三位。值得注意的是,得益于其在混合基金、货币基金及海外投资的突出表现,华夏基金相较一季度利润环比增长超10%。
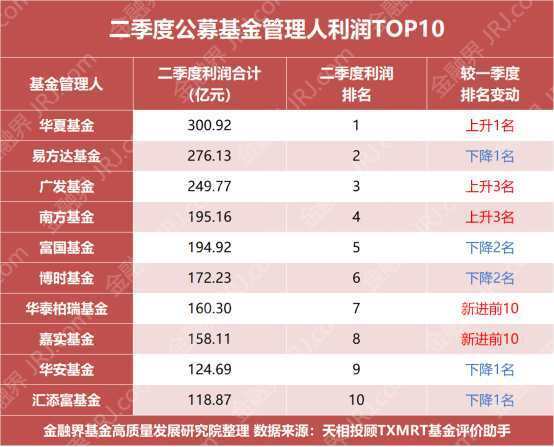
百亿利润阵营扩容,南方、富国、博时、华泰柏瑞、嘉实、华安、汇添富、国泰等机构均跻身其中。
从排名变动来看,相较于一季度,华泰柏瑞基金、嘉实基金新进利润榜前十,工银瑞信基金、中欧基金则退出利润榜前十。广发基金、南方基金排名实现上升3位,富国基金、博时基金、华安基金、汇添富基金则排名下降1位。
本文源自:金融界
作者:AI言心


