我估计很多人都还不知道。
国产影视剧市场,终于迎来了一部大剧。

央视一套黄金档播出《》,接档《》开播,佟瑞欣、马晓伟、金鑫、温海波,连奕名、罗勇等7位知名演员助阵。
不过,大家也不用疑惑,因为在今天之前,我也不知道,很多人都不知道。因为,这部剧是突然空降的一部大剧,属于搞突然袭击。

而众所周知,央视的眼光一贯不错,比如正在热播的《我是刑警》就是央视看重的剧集,这才播出几集,就已经成功火遍全国成了爆款。
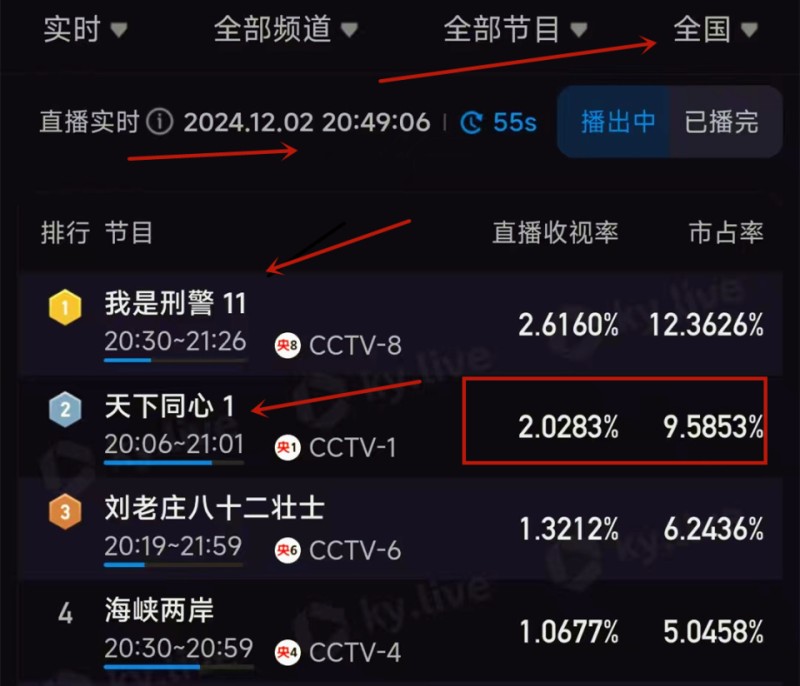
这部《天下同心》在央视一套开播,才播2集,收视破2。话说央视的剧真是一部接着一部,《西北岁月》还在回味,《天下同心》这就接档了,终于又有让我熬夜狂追的历史剧了。

《天下同心》作为革命历史题材,故事大家都知道,不用我赘述!
这部剧的主线剧情是1949年第一届中国人民政治协商会议的筹备与召开为主线。
新中国成立伊始,排除万难!主要讲述了中国共产党与各民主党派、各人民团体、社会贤达排除万难、勠力同心,携手共建新中国的故事!

其他的剧集,可能第一看点是演员,但对于这部《天下同心》,第一看点就是剧情。
1948 年,中国共产党在河北保定发表了《五一宣言》,发出了打倒国民党反动派、迅速召开新的政治协商会议、成立民主联合政府的号召,得到了各民主党派的积极响应。

同年,辽沈战役爆发,东北野战军在共产党的正确领导下取得胜利,并南下入关,国民党军队被迫撤军稳定江南。
紧接着,淮海战役打响,国民党军队节节败退,蒋介石以退为进,辞去总统职位让给李宗仁,但这也无法挽回其败局,中国共产党赢得淮海战役的胜利,长江以北再无大规模战事,解放战争的局势逐渐明朗化。

1949 年 1 月,国民党将领傅作义深明大义,主动投降,北平和平解放,为新政协会议在北平的召开创造了有利条件。

与此同时,中国共产党积极筹备新政协会议,各民主党派和无党派人士在共产党的诚恳邀请下,历经艰险,纷纷奔赴北平,共商建国大业。

而国民党大势已去,却仍妄图作垂死挣扎,撤往台湾的同时,下令特务杀害民主人士,但这也无法阻挡历史前进的车轮.
1949 年 4 月 20 日,南京政府拒绝签署国内和平协定,谈判破裂,渡江战役随即打响,中国人民解放军百万雄师以排山倒海之势强渡长江。

仅用两天就取得了胜利,解放了南京,宣告了国民党反动统治的覆灭。
5 月,上海解放。1949 年 9 月 21 日,中国人民政治协商会议第一届全体会议在北京隆重召开,各党派、各阶层代表齐聚一堂,共同商讨新中国的建设大计。

1949 年 10 月 1 日,中华人民共和国开国大典在北京天安门广场隆重举行,毛泽东主席向全世界庄严宣告:“中华人民共和国,中央人民政府,今天成立了!
从此,中国人民站起来了,中华民族的历史翻开了崭新的一页。

《天下同心》的第二大看点就是阵容
该剧的导演是董亚春,也是一位大导演,尤其擅长革命历史剧题材。这几年比较火的《》,还有《》都是他的代表作,实力雄厚,风格硬朗。

另外,《天下同心》作为革命历史剧题材。
谁来当特型演员,谁来扮演毛主席,那就是本剧的一大看点。

这个看点,放在之前,那基本上都是,而近几年随着唐国强年事已高,其他演员也逐渐有了起色。比如候京健,再比如王仁军,当然还有参演本剧的佟瑞欣。
其一,唐国强

唐国强在外形上不断打磨,尽可能地贴近毛泽东的形象特征,包括面部表情、肢体语言等。
经过多次出演,他在体态、神情等方面都与毛泽东有较高的相似度,能够让观众在视觉上产生直观的认同感。

唐国强在深入挖掘毛泽东的内在气质方面,也颇有建树。
他能通过细腻的表演展现出毛泽东作为领袖的独特神韵,如毛泽东的雄才大略、诗人气质、幽默风趣以及亲和近人等特质,都被唐国强演绎得十分到位,使观众能够感受到伟人的风采和魅力。

其二,候京健
侯京健外形上与青年毛泽东有一定的相似度,其长相周正,五官轮廓分明,尤其是眉眼之间的神韵,能够较好地展现出毛泽东的英气与睿智,为角色的塑造奠定了良好的基础。
在《》中,他的扮相让观众眼前一亮,不少观众评价其外形神似青年时期的毛泽东.
另外,侯京健也善于发现。

他通过深入研读大量资料以及深入当地农村体验生活,用心揣摩毛泽东的行为思想,从而在气质上也做到了较好的还原 。
他成功地展现出了毛泽东身上所具有的那种独特的气质,如在《觉醒年代》中,将毛泽东的朝气蓬勃、胸怀大志以及忧国忧民的神情刻画得十分到位,使观众能够真切地感受到青年毛泽东的精神风貌。

其三,
王仁君注重细节,善于通过一些细微的动作和表情来展现毛泽东的内心世界。
例如在《问苍茫》中,有一场夫妻在河边互诉衷肠的戏,他在克制中流下的一行泪,很好地表现了毛泽东作为一个丈夫的深情以及在艰难处境下的复杂情感。

王仁君的表演在一定程度上摆脱了以往对毛泽东等伟人形象的刻板塑造方式,更加注重从人性化、生活化的角度去刻画人物。

他在《问苍茫》中展现了毛泽东作为一个 “奶爸” 的形象,以及在事业与家庭之间的权衡与取舍,使毛泽东的形象更加立体、丰满,贴近生活,让观众看到了伟人平凡而又真实的一面。

其四,佟瑞欣
佟瑞欣有着丰富的演艺经验,能够熟练地运用表演技巧,将自己融入到角色中,其表演自然而不刻意,举手投足间都散发着毛泽东的独特魅力,使观众在观看过程中能够更加专注于剧情和角色本身,而不会因为表演的生硬或做作而产生出戏的感觉。

佟瑞欣对角色理解深刻。
他不仅仅是在表面上模仿毛泽东的言行举止,而是深入挖掘角色背后的历史背景和人物内心世界,通过自己的理解和诠释,展现出毛泽东在不同历史时期的思想变化和情感起伏,让观众对毛泽东这一历史人物有了更全面、更深入的认识。

在《天下同心》中,马晓伟扮演蒋介石,同样也是大家的老熟人。谈及扮演蒋介石的演员,可谓是众说纷纭,难分伯仲,每个人心中都有那独属的最佳演绎者呀。

《》三部曲中,赵恒多将蒋介石刻画得形神皆备,臻于极致。他那深厚扎实的台词功底,宛如点睛之笔,为角色注入了灵动的神韵,使之更加鲜活立体。
当然,亦有众多人对孙飞虎的演绎青睐有加。

不少观众皆认为,在众多特型演员之中,孙飞虎于外形上与蒋介石的相似度堪称最高呀。他所主演的《重庆谈判》以及 1990 版的《》,皆是影史经典瑰宝。
除此之外呀,陈道明、张国立,乃至等诸多实力派演员,亦曾演绎过蒋介石这一角色,且各自拥有不少忠实的支持者。

他们各有千秋,或于气质上拿捏精准,或于情感表达上细腻入微,或于举手投足间彰显神韵,皆将蒋介石的形象演绎得活灵活现
相较于前文提及的诸位名角,马晓伟的名气或许略显逊色,然其演技实力却着实不容小觑呀。

马晓伟一登场,那独特的气场便扑面而来,瞬间与其他角色区分开来,令人眼前一亮。
他所塑造的蒋介石,同样形神俱佳,细腻入微的表演,使得人物形象跃然眼前,同样出彩!

同样还是大平台,同样都是革命历史剧,演员阵容也是同样雄厚,《天下同心》接档《西北岁月》,喜欢此类题材的观众不用担心剧荒了,可以无缝衔接,一次看个够。
并且,我也相信,这部《天下同心》也有爆款潜质,能够延续《西北岁月》的热度。
那么,你最近在看哪部国产剧?
是《我是刑警》,还是什么?
欢迎大家一起留言讨论!

